MySQL performance tuning
MySQL, tuning | March 28, 2013
Dit artikel is geschreven voor Intracto en verscheen voor het eerst op de Intracto blog op Maart 28, 2013.
In de traditionele LAMP (Linux Apache MySQL PHP) stack, waar we onze websites op draaien, is de database een belangrijk element in het performant werken van een applicatie. De meeste standaard systemen, zoals Drupal en Magento, stellen vaak een aantal instellingen voor. Maar, een applicatie is zelden standaard, en datasets zijn onderhevig aan verandering. Hierdoor is de ideale configuratie vaak een utopie. Goede opvolging, bijvoorbeeld via monitoring is dan ook vereist om je applicatie gezond te houden. In dit artikel overlopen we een aantal inzichten in database tuning bij PHP web applicaties.
Er zijn een aantal plaatsen waar optimalisatie mogelijk is. Enerzijds is er de MySQL server zelf, waar de administrator de server parameters kan bijsturen. Aan de andere kant zijn er ook de queries die de MySQL server te verwerken krijgt. Hier kan de developer, eventueel geassisteerd door de administrator, ook vaak verbeteringen aanbrengen. Wat betreft de keuze van hardware en ook op Linux kernel niveau, kunnen we rekenen op onze hosting partners. Zij hebben de nodige kennis in huis om ons te begeleiden en hierin de juiste keuzes te helpen maken.
MySQL versies
Bij de overname van Sun door Oracle in 2009, veranderde ook MySQL van eigenaar. Aangezien Oracle een slechte reputatie heeft in de Open-Source wereld, werd deze overname niet door iedereen toegejuicht. Er werd dan ook meteen gestart met een volledig vrije fork van MySQL, genaamd MariaDB. Deze versie tracht zo goed mogelijk compatibel te blijven met MySQL zelf, zodat men zeer eenvoudig kan overstappen van MySQL naar MariaDB.
Er werden nog een aantal andere forks gemaakt, waaronder Percona Server en Drizzle. Deze proberen elk ook op hun manier een meerwaarde te bieden ten opzichte van de standaard MySQL. Vooral Percona is interessant, aangezien zij ook een toolkit ter beschikking stellen om MySQL en afgeleiden te tunen. Verder stelt Percona via hun corporate website en mysqlperformanceblog.com een groot aantal resources ter beschikking in verband met optimalisatie. Ook het O'Reilly boek "High Performance MySQL" werd mede geschreven door Percona medewerkers.
Een aantal Linux distributies heeft al aangekondigd dat ze in de toekomst met MariaDB als standaard MySQL implementatie zullen uitkomen. Dit is dus iets wat we moeten blijven opvolgen. Bij Intracto baseren we ons op Debian en gebruiken we tot op heden MySQL 5.1, wat de standaard is in Debian 6.
Storage engines
MySQL stelt een aantal storage engine's ter beschikking. De belangrijkste zijn InnoDB en MyISAM. Zij hebben elk een eigen manier om met database tabellen te werken. MyISAM is de oudere, eenvoudige engine en was vroeger de standaard. InnoDB is vandaag de dag de standaard en is iets verfijnder, zo kan deze op rij niveau een lock uitvoeren, terwijl MyISAM dit slechts op tabel niveau kan. Dit heeft ook zo zijn effect bij het nemen van live database dumps. Verder is InnoDB transactioneel terwijl MyISAM dit niet is. Dit heeft zo zijn voordeel bij crash recovery's. Je kan een storage engine per tabel kiezen, zo is het ook mogelijk om storage engines binnen een zelfde database door elkaar te gebruiken. We verkiezen om, net zoals Drupal en Magento, zo vaak als mogelijk vast te houden aan InnoDB.
Op MariaDB worden er buiten MyISAM en InnoDB nog extra storage engines aangeboden. De belangrijkste zijn hier Aria en XtraDB. Aria is een crash-safe verbetering van MyISAM. In de toekomst wil men van Aria ook een volledig transactionele storage engine maken, vergelijkbaar met InnoDB. De XtraDB storage engine werd ontwikkeld door Percona. XtraDB is een verbetering van InnoDB en voegt extra features toe in verband met tuneability en scaleability.
Tuning scripts
Bij het tunen van een MySQL server kan je beginnen met alle variabelen manueel te controleren en na te tellen of deze in verhouding zijn met de aanwezige dataset. Maar, je kan ook een eenvoudigere start nemen door een tuning primer script zoals MySQLTuner en MySQL-Tuning-Primer te draaien. Deze gaan de belangrijkste parameters controleren en vaak al betere waardes voorstellen. Je kan vervolgens de gerapporteerde parameters opzoeken in de MySQL documentatie en nagaan of je de parameter al dan niet wilt bijsturen.
Parameters
Er zijn zeer veel parameters die je kan bijsturen. Hieronder worden de belangrijkste parameters overlopen. Let wel op wanneer je parameters gaat aanpassen op basis van server status variabelen, de server moet steeds minstens 24h draaien om een realistisch beeld te hebben van de server status.
InnoDB onderhoudt in het geheugen een buffer pool met cached data en indexen. Als de machine voldoende geheugen heeft, is het aangewezen om de innodb_buffer_pool_size minstens zo groot te maken als de som van alle InnoDB data en index space samen. Je kan dit aantal makkelijk berekenen via volgende query:
SELECT round((sum(data_length + index_length) / 1024 / 1024), 2) "Size in MB" FROM information_schema.TABLES WHERE table_schema = "<db_name>" and engine = "InnoDB"
De InnoDB buffer pool is veruit de belangrijkste optie voor InnoDB performantie, maar is zeker niet de enige. Zo kan het verhogen van innodb_flush_log_at_trx_commit naar 2 een gunstig effect hebben bij schrijf-intensieve workloads, bijvoorbeeld als er grote imports draaien.
Parameter innodb_flush_method kan je wijzigen naar O_DIRECT. Maar, volgens mijn ervaringen heeft dit maar weinig invloed, en is het niet de moeite om hiervoor af te wijken van de standaard waarde.
Een andere parameter, die niet zozeer met performantie te maken heeft, is innodb_file_per_table. Standaard zal InnoDB één groot bestand aanmaken voor de tablespace van alle tabellen. Je kan de tablespace echter niet reclaimen. Het bestand kan alleen maar groeien, ook als je tabellen opschoont. Door innodb_file_per_table in te stellen, wordt er per tabel een bestand aangemaakt voor de tablespace. Je hebt zo meer controle op de groei van deze bestanden en kan deze makkelijk reclaimen door individueel een tabel te droppen en opnieuw aan te maken.
Voor MyISAM is de belangrijkste parameter key_buffer_size. Het is aangewezen om deze parameter minstens zo groot te maken dan het totaal van je MyISAM indexen. Je kan dit aantal makkelijk berekenen via volgende query:
SELECT round((sum(index_length) / 1024 / 1024), 2) "Size in MB" FROM information_schema.TABLES WHERE table_schema = "<db_name>" and engine = "MyISAM"
De parameter table_open_cache stelt het aantal open tabellen in voor alle threads. Je kan deze waarde bijsturen op basis van de waarde van de opened_tables. Als opened_tables te hoog is, wil dit zeggen dat de table_open_cache waarschijnlijk te laag ingesteld staat. Je kan deze parameter in feite niet te hoog instellen, zolang je niet het maximum open file descriptors van je kernel overschrijd. Hetzelfde geldt voor de parameter table_definition_cache. Deze kan je ook bijsturen op basis van de waarde opened_table_definitions.
De tmp_table_size parameter bepaalt hoeveel geheugen er gebruikt mag worden voor in-memory temporary tables. Dit type van tabel wordt bijvoorbeeld achter de schermen aangemaakt wanneer je gebruik maakt van GROUP BY. Als een in-memory tabel groter wordt dan tmp_table_size, word deze automatisch op de harde schijf geplaatst als MyISAM tabel. De tmp_table_size wordt ook beperkt door max_heap_table_size. Als je de tmp_table_size verhoogt, moet je de max_heap_table_size mee verhogen.
Via query_cache_size en query_cache_limit kan je het geheugen configureren dat voor het cachen van query resultaten gebruikt wordt. Parameter query_cache_size bepaalt de grootte van de cache, terwijl query_cache_limit een beperking instelt op de grootte van resultaten. Als een resultaat groter is dan query_cache_size, dan wordt het resultaat niet gecached. Let op, vaak zullen applicaties zelf ook resulaten cachen (bijvoorbeeld in APC, memcache, ...), waardoor je mogelijk dubbele caching hebt.
Met de parameter join_buffer_size kan je de grootte van de buffer sturen die gebruikt wordt bij full joins en dergelijke. Ook bijvoorbeeld wanneer er joins gebeuren die geen gebruik maken van indexen zal dit resulteren in een full table scan en wordt deze buffer gebruikt. Als er veel joins gebruikt worden zonder indexen kan je de join_buffer_size aanpassen. De beste manier om snelle joins te krijgen is echter door juiste indexen toe te voegen.
MySQL heeft een sort buffer die gebruikt wordt als er geen indexen beschikbaar zijn, en er gesorteerd moet worden. De grootte van deze buffer kan je aansturen via de sort_buffer_size parameter. Je doet dit op basis van de waarde van de sort_merge_passes status variabele. Maar, de sort_buffer_size stel je idealiter in op sessie niveau, aangepast aan de queries die uitgevoerd worden, en niet globaal.
Als laatste kan je ook de parameter thread_cache_size bijsturen. Dit doe je op basis van de threads_created status variable. Het is de bedoeling dat de connection manager zelf geen threads moet aanmaken, maar dat hij deze uit de thread cache kan halen.
Slow queries
Via SHOW PROCESSLIST kan je op de MySQL server zien welke queries er draaien. Dit is natuurlijk geen efficiente manier om trage queries op te sporen. MySQL heeft hiervoor een "slow query log". Je kan dit log activeren door de parameter slow_query_log op ON te zetten. Dit kan at runtime via SET GLOBAL slow_query_log = 'ON'. Alle queries die langer draaien dan long_query_time worden daarna gelogd in het bestand slow_query_log_file. De long_query_time kan je best zelf nog lager instellen, aangezien deze standaard op 10 seconden staat ingesteld. Je kan ook nog de parameter log_queries_not_using_indexes op ON zetten als je alle queries die geen gebruik maken van indexen altijd mee in de log wilt opnemen.
De gelogde queries kan je vervolgens via EXPLAIN verder analyseren. EXPLAIN wordt in een volgende paragraaf in detail besproken.
MySQL heeft ook een profiler aan boord die je kan activeren per sessie via SET profiling = 1. Vervolgens voer je dan één of meerdere queries uit, die door de profiler opgepikt worden. De lijst met queries die in de huidige sessie geprofiled werden, kan je verkrijgen met SHOW PROFILES. Je kan dan het profile van een bepaalde query in detail opvragen via SHOW PROFILE FOR QUERY 2, of gewoon SHOW PROFILE voor de meest recente query. De uitvoer kan er dan bijvoorbeeld als volgt uit zien:
+--------------------------------+----------+ | Status | Duration | +--------------------------------+----------+ | starting | 0.000039 | | Waiting for query cache lock | 0.000011 | | checking query cache for query | 0.000093 | | checking permissions | 0.000015 | | Opening tables | 0.000036 | | System lock | 0.000017 | | Waiting for query cache lock | 0.000052 | | init | 0.000045 | | optimizing | 0.000018 | | statistics | 0.000024 | | preparing | 0.000022 | | executing | 0.000011 | | Sending data | 0.001833 | | end | 0.000015 | | query end | 0.000010 | | closing tables | 0.000015 | | freeing items | 0.000019 | | Waiting for query cache lock | 0.000007 | | freeing items | 0.000029 | | Waiting for query cache lock | 0.000007 | | freeing items | 0.000006 | | storing result in query cache | 0.000008 | | logging slow query | 0.000006 | | cleaning up | 0.000007 | +--------------------------------+----------+ 24 rows in set (0.00 sec)
De MySQL slowlog en profiler zijn vrij beperkt, zo kan je de long_query_time bijvoorbeeld niet op minder dan 1 seconde instellen. Wat op zich nog zeer traag is voor een query, zeker als het een query is die vaak opgeroepen wordt. MySQL heeft standaard niet veel extra's aan boord om fijner te kunnen werken. Je kan daarom best een gespecialiseerde toolkit installeren waarmee je dit wel kan.
Percona toolkit
Percona Toolkit voor MySQL is een samensmelting en voortzetting van Maatkit en Aspersa. De toolkit bevat een collectie van command-line tools, waarmee geavanceerde server taken uitgevoerd kunnen worden. De toolkit bevat ook een aantal tools voor performance tuning.
Er zijn scripts die de server configuratie en status bekijken, zoals bijvoorbeeld pt-summary en pt-mext. Zo kan je bijvoorbeeld via pt-mext de status variabele Handler_read_rnd_next analyseren en het gebruik van full table scans detecteren.
Andere scripts spitsen zicht toe op queries zelf. Zo is er het script pt-index-usage dat een query log inleest en het gebruik van indexen in queries analyseert. Een ander script is pt-query-advisor dat queries uit een log analyseert en adviezen per query afprint. Een kort voorbeeld van de uitvoer:
ALI.001 0x06D9A552EB8EC098 0x474C4BDFDEC4AAC1 0x662697DA919D72DA 0x742D4DAFC2C11E26 ARG.001 0x06D9A552EB8EC098 CLA.001 0x742D4DAFC2C11E26 # Profile # Query ID NOTE WARN CRIT Item # ================== ==== ==== ==== ========================================== # 0x06D9A552EB8EC098 1 1 0 select count(?_.id) as sclr? from book ?_ where ?_.title like ? # 0x474C4BDFDEC4AAC1 1 0 0 select t?id as id?, t?name as name? from topic t? inner join bookstopics on t?id = bookstopics.topic_id where bookstopics.book_id = ? # 0x662697DA919D72DA 1 0 0 select t?id as id?, t?ventdate as eventdate?, t?status as status? from calendar t? where t?ventdate = ? # 0x742D4DAFC2C11E26 1 1 0 select sum(l?_.fine) as sclr? from lending l?_
Je ziet dat er een melding ALI.001 wordt gemaakt op de 4 queries die geanalyseerd werden. Als we deze regel opzoeken in de manual page, dan leren we dat dit wil zeggen dat er aliases gebruikt zijn zonder gebruik te maken van het AS keyword. Het argument hiertegen is dat het gebruik van AS de leesbaarheid bevorderd. Dit is slechts een nota, dus niet zo erg belangrijk.
Er worden ook warnings gegeven. Namelijk een ARG.001 bij query 0x06D9A552EB8EC098, deze regel duid aan dat er een argument gebruikt werd met een leading wildcard, zoals "%foo". Het argument hiertegen is dat dit er voor zorgt dat een query hierdoor geen gebruik kan maken van indexen.
Als laatste zien we bij query 0x742D4DAFC2C11E26 een warning CLA.001. Deze regel duid aan dat er een SELECT gedaan wordt, zonder gebruik te maken van een WHERE, waardoor er mogelijk meer rijen geëvalueerd moeten worden dan nodig.
Nog een andere tool is pt-query-digest en is waarschijnlijk mijn favoriet. Deze tool analyseert queries en genereert rapporten. Je kan deze ook weer een query log meegeven of, hem rechtstreeks de MySQL packets laten onderscheppen via tcpdump. Als je de tcpdump optie wil gebruiken, moet je er wel voor zorgen dat je de connection parameter van je websites instelt op 127.0.0.1 in plaats van localhost. Omdat er anders via het UNIX domain socket verbinding gemaakt wordt en het verkeer bijgevolg niet via de loopback interface passert. Een voorbeeld:
timeout 60 tcpdump -i lo port 3306 -s 65535 -x -n -q -tttt > pt.log; pt-query-digest --type=tcpdump pt.log
Je krijgt dan als uitvoer een runtime samenvatting van de queries die gedraaid hebben:
# Overall: 96 total, 22 unique, 12 QPS, 0.01x concurrency ________________ # Attribute total min max avg 95% stddev median # ============ ======= ======= ======= ======= ======= ======= ======= # Exec time 116ms 0 60ms 1ms 1ms 6ms 93us # Lock time 0 0 0 0 0 0 0 # Rows sent 0 0 0 0 0 0 0 # Rows examine 0 0 0 0 0 0 0 # Query size 13.52k 14 523 144.20 313.99 90.81 136.99
Vervolgens wordt er een ranking gemaakt van de queries zelf:
# Rank Query ID Response time Calls R/Call Apdx V/M Item # ==== ================== ============= ===== ====== ==== ===== ========== # 1 0x474C4BDFDEC4AAC1 0.1062 91.5% 33 0.0032 1.00 0.03 SELECT Topic BooksTopics # 2 0x5D51E5F01B88B79E 0.0030 2.6% 4 0.0008 1.00 0.00 ADMIN CONNECT # 3 0xC22D7D2ABF28ECA2 0.0021 1.8% 19 0.0001 1.00 0.00 SELECT Author # MISC 0xMISC 0.0047 4.1% 40 0.0001 NS 0.0 <19 ITEMS>
Waarna er verder gegaan wordt met een individueel rapport per query. Je krijgt zo een goed beeld van welke queries er lang draaien en hoe vaak ze opgeroepen worden. Zo kan je pijnpunten blootleggen en gericht beginnen met het optimaliseren van queries. pt-query-digest is overigens niet gelimiteerd aan rapporteren, maar kan ook queries replayen etc.
Indexen
De snelheid van queries hangt vaak af van het aanwezig zijn van correcte indexen. Als we de vergelijking maken met een boek, bijvoorbeeld over Belgische bieren, dan ga je ook niet heel het boek van voor naar achter doorbladeren als je op zoek bent naar informatie over "Westmalle Tripel". Je zoekt het woord op in de index en komt zo op de juiste pagina terecht. MySQL indexen zijn altijd een soort van tree, dit wil zeggen dat ze vergelijkbaar zijn met de werking van een index in een boek.
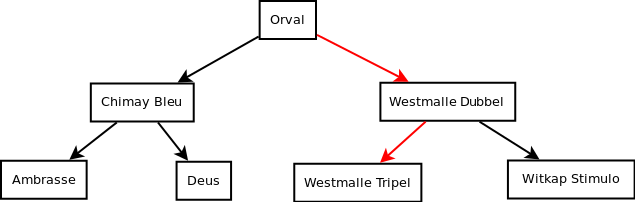
Als we op zoek gaan naar "Westmalle Tripel". Doen we eerst de index open, in dit geval kwamen we terecht op de positie "Orval", we moeten dan kiezen tussen "Chimay Bleu" en "Westmalle Dubbel". Aangezien de "W" van "Westmalle" aan de kant van de "W" ligt, gaan we die richting uit. We herhalen dit process tot we bij het resultaat "Westmalle Tripel" zijn aangekomen.
Het probleem bij het gebruik van MySQL indexen is echter dat een query LIKE 'West%' gebruik kan maken van een index, maar een query LIKE '%malle' niet. Bovendien komt er nog bij dat wanneer je een tekstveld gebruikt in een index, je moet aangeven hoeveel karakters je wilt opnemen in de index. De lengte van een index key is namelijk beperkt, op 768 bytes bij InnoDB. Bovendien wil je de index zo klein mogelijk houden, zodat deze goed in het geheugen past.
Een aantal MySQL storage engines zoals MEMORY, ondersteunen ook hash indexen. Deze kunnen vaak ook een zeer efficiente oplossing bieden. Maar, aangezien zowel InnoDB als MyISAM dit niet ondersteunen laat ik dit verder buiten beschouwing van dit artikel. Je zou ook hash indexen kunnen emuleren, door zelf kolommen met berekende hashes toe te voegen, maar dat wordt niet frequent toegepast.
Een laatste type index, en niet de minst interessante, is de text index. MyISAM ondersteunt dit, zodat we full-text search kunnen doen. InnoDB ondersteunt ook full-text indexen, maar pas sinds MySQL versie 5.6. Een FULLTEXT index kan je toevoegen op een CHAR, VARCHAR, of TEXT veld. Kort gezegd kan je er hiermee voor zorgen dat bepaalde searches die je anders zou schrijven als LIKE '%...%' via een index verlopen, en daardoor versneld worden. Onderstaand voorbeeld zou "Hellen Vreeswijk" terugvinden, maar ook "Gillian Cross" en "Ruby Cross":
ALTER TABLE author ADD FULLTEXT(name); SELECT name FROM author WHERE MATCH(name) AGAINST('Vreeswijk,Cross');
De MySQL FULLTEXT heeft echter zijn beperkingen, zo werkt deze niet performant op grote datasets en zijn de features beperkt. Relationele databases zijn simpelweg niet ontworpen om full-text op uit te voeren. Wanneer full-text search nodig is, doen we dit bij Intracto met Apache Solr. Solr gebruikt de Lucene Java search library voor full-text indexing en search. Solr is eigenlijk een uitbreiding op Lucene en voegt extra features toe zoals hit highlighting, faceted search, suggesties (did you mean ...), geospatial search en nog veel meer.
Explain
Bovenstaande tools helpen je om queries te vinden die niet performant zijn en geoptimaliseerd dienen te worden. Maar, hoe optimaliseer je dan een query? MySQL heeft hier het EXPLAIN statement voor. EXPLAIN toont je het query execution plan voor een SELECT query, dit plan bevat informatie over hoe de query verwerkt zal worden, hoe tabellen gejoined worden en in welke volgorde dit gebeurt. Dit plan helpt je om te begrijpen waar je indexen moet toevoegen om de query sneller te laten lopen.
Je kan explain enkel op SELECT queries gebruiken. Vanaf MySQL 5.6 worden INSERT, UPDATE, REPLACE en DELETE statements ook ondersteund. In oudere versies van MySQL moet je de queries herschrijven naar SELECTs om ze te kunnen analyseren met explain. Via de EXTENDED optie kan je extra informatie verkrijgen over het percentage van rijen dat gefilterd wordt door een conditie. Een voorbeeld om je een idee te geven hoe je hier mee aan de slag moet:
EXPLAIN EXTENDED SELECT title FROM book JOIN author WHERE author.name = 'Hanne%' \G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: author type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 655 filtered: 100.00 Extra: Using where *************************** 2. row *************************** id: 1 select_type: SIMPLE table: book type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 1328 filtered: 100.00 Extra: Using join buffer
Als ik deze query nu uitvoer, dan is deze zeer snel (0,00 seconden). Maar, dat wil niet zeggen dat het een goede query is. De dataset is in dit geval klein, maar als mijn dataset groeit, zal deze query een probleem vormen. De explain toont aan dat er een table scan gebeurt (type: ALL) en dat de join op de book table momenteel 1328 rijen moet doorzoeken. Bovendien merken we ook op dat er gebruik gemaakt wordt van een join buffer. We kunnen de query verbeteren door een join conditie op te geven:
EXPLAIN EXTENDED SELECT title FROM book JOIN author ON author.id = book.authorId WHERE author.name = 'Hanne%' \G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: author type: ALL possible_keys: PRIMARY key: NULL key_len: NULL ref: NULL rows: 655 filtered: 100.00 Extra: Using where *************************** 2. row *************************** id: 1 select_type: SIMPLE table: book type: ref possible_keys: IDX_6BD70C0FA196F9FD key: IDX_6BD70C0FA196F9FD key_len: 5 ref: readingCorner.author.id rows: 1 filtered: 100.00 Extra: Using where
De book join maakt nu gebruik van de primary key index en we zien dat er hierdoor nog maar 1 rij doorzocht moet worden. De where op de author tabel moet nog wel 655 rijen overlopen, en ook hier gebeurt een table scan. Dit kunnen we verbeteren door een index toe te voegen op het "name" veld. Het veld zelf is gedefinieerd als een VARCHAR(255), maar om de index zo klein mogelijk te houden, voegen we maar op de eerste 6 karakters een index toe. Deze lengte is iets wat je zelf moet afwegen, als de query bijvoorbeeld achter een autocomplete veld zit, is 6 karakters wel realistisch.
CREATE INDEX author_name on author (name(6)); EXPLAIN EXTENDED SELECT title FROM book JOIN author ON author.id = book.authorId WHERE author.name = 'Hanne%' \G; *************************** 1. row *************************** id: 1 select_type: SIMPLE table: author type: ref possible_keys: PRIMARY,author_name key: author_name key_len: 20 ref: const rows: 1 filtered: 100.00 Extra: Using where *************************** 2. row *************************** id: 1 select_type: SIMPLE table: book type: ref possible_keys: IDX_6BD70C0FA196F9FD key: IDX_6BD70C0FA196F9FD key_len: 5 ref: readingCorner.author.id rows: 1 filtered: 100.00 Extra: Using where
Het EXPLAIN statement is het belangrijkste hulpmiddel bij het analyseren van een query. In een volgende blogpost zullen we dan ook dieper ingaan op dit statement.